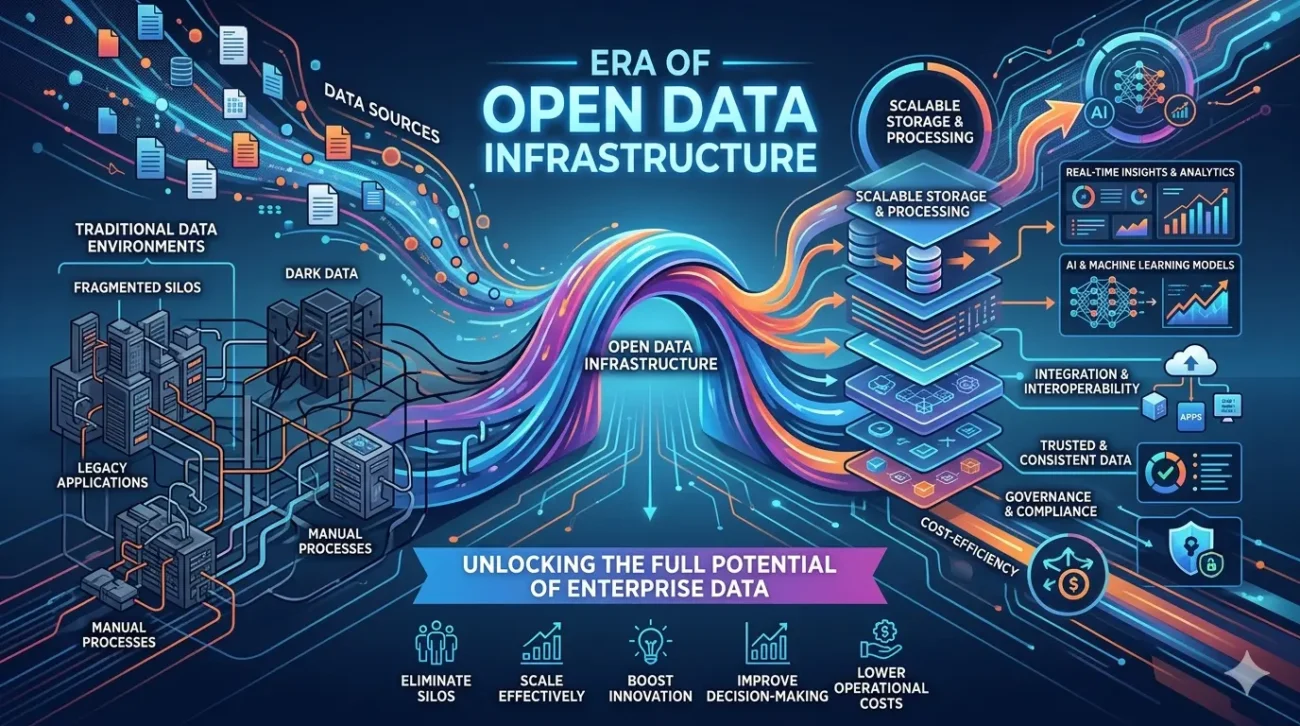
For most organisations, data is everywhere—but usable insight is not. Vast amounts of information are collected daily from applications, systems, and customers, yet a large portion of it sits idle. This unused or “dark” data quietly limits decision-making, slows down innovation, and weakens the impact of analytics and AI initiatives. The problem isn’t data availability—it’s how that data is structured, accessed, and trusted.
Traditional data environments were never designed for the scale and speed businesses operate at today. Over time, systems became layered, fragmented, and siloed. Data ended up spread across multiple platforms, stored in different formats, and governed inconsistently. Even when organisations invest in analytics tools, they often struggle to get timely, reliable insights because the underlying data is not ready.
This is where open data infrastructure begins to change the equation.
Instead of locking data into rigid systems, open infrastructure introduces flexibility. It allows organisations to separate how data is stored from how it is processed. This simple shift has a significant impact. Teams can scale storage without affecting performance, choose the right tools for analysis, and avoid being tied to a single platform. More importantly, it makes data easier to access and use across the business.
As data becomes more accessible, the way it is managed also evolves. Manual processes are gradually replaced with automated pipelines that continuously move, validate, and transform data. Rather than waiting for batch updates or manual intervention, organisations start working with data that is consistently fresh and reliable. Errors are detected early, changes are tracked, and updates flow through the system without disruption.
This level of consistency builds something that many organisations struggle with—trust in data. When teams are confident that the data they are using is accurate and up to date, decision-making becomes faster and more effective. Instead of questioning numbers, they focus on acting on them.
Another important shift is how easily data can be integrated. Modern businesses rely on multiple tools and platforms, from cloud systems to third-party applications. Bringing all this data together has traditionally been complex and time-consuming. Open infrastructure simplifies this by enabling smoother connections between systems. Data flows more freely, and insights are no longer delayed by integration challenges.
This has a direct impact on how quickly businesses can respond to change. Whether it’s tracking customer behaviour, monitoring operations, or analysing market trends, real-time or near real-time access to data allows organisations to act immediately instead of reacting too late.
At the same time, visibility and control improve. With clearer data lineage, organisations can understand where data comes from, how it changes, and how it is used. This makes governance more practical and compliance easier to manage. Security also becomes stronger because access and usage can be monitored more effectively across the entire data lifecycle.
The importance of this approach becomes even more evident in multi-cloud environments. Many organisations now operate across different platforms to optimise performance and cost. Without a flexible data foundation, managing this complexity can become a major challenge. Open data infrastructure allows data to move and operate across environments without friction, making the system more adaptable and resilient.
As a result, data starts to play a more active role across the business. It moves beyond reporting and becomes part of everyday decision-making. Teams are no longer dependent on delayed insights or static dashboards. Instead, they work with live data that reflects what is happening in real time.
This is particularly important for advanced use cases like artificial intelligence and machine learning. These technologies depend heavily on high-quality, well-structured data. When data is fragmented or unreliable, AI outcomes suffer. But when supported by a strong, open infrastructure, these systems become more accurate, scalable, and valuable.
There is also a cost dimension that cannot be ignored. Inefficient data systems often lead to unnecessary storage and processing costs, especially in cloud environments. When data is duplicated, poorly organised, or difficult to access, it increases the resources required to manage it. Open infrastructure helps reduce this inefficiency by improving how data is stored and processed, ultimately lowering operational costs.
What makes this shift important is that it is not just technical—it is strategic. Organisations that can access and use their data effectively have a clear advantage. They move faster, make better decisions, and adapt more easily to change. Those that cannot are often held back by the very data they invested in.
Open data infrastructure addresses this gap by turning data into something that is not just stored, but actively used. It removes barriers, improves reliability, and creates a foundation where data can support growth instead of slowing it down.
The reality is that most organisations already have the data they need. The challenge is unlocking it. By moving towards a more open, flexible, and scalable approach, businesses can finally bring their data to life—turning what was once unused into a powerful driver of insight, innovation, and long-term success.