In modern analytics environments, data modelling decisions have a direct impact on performance, cost, and scalability. One of the most common yet often overlooked design choices is whether to use wide tables or narrow tables. While both approaches serve valid purposes, choosing the wrong structure for your workload can quietly increase compute costs, slow down queries, and complicate data pipelines.
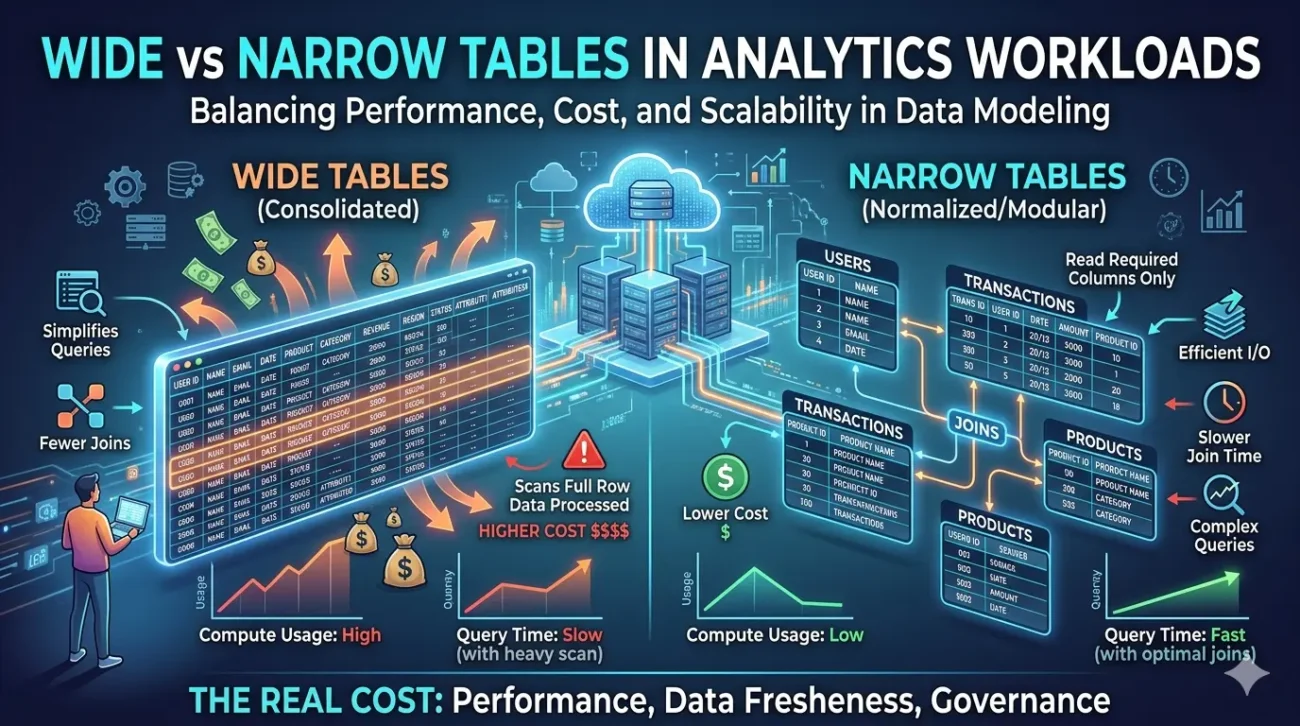
A wide table contains a large number of columns, often consolidating multiple data points into a single structure. This approach is typically used to simplify reporting, reduce joins, and create a single source of truth for business users. At first glance, wide tables appear efficient—fewer joins mean simpler queries and faster dashboard development. However, this simplicity comes at a cost. Query engines often scan entire rows even when only a few columns are needed, leading to unnecessary data processing. In large-scale environments, this results in higher storage I/O, increased compute usage, and ultimately, higher cloud costs.
On the other hand, narrow tables follow a more normalized or modular structure, where data is split across multiple tables with fewer columns. This approach aligns closely with scalable data architecture principles, particularly in distributed and cloud-based systems. Narrow tables allow query engines to read only the required columns, improving performance and reducing resource consumption. They are also more flexible when handling schema changes, making them ideal for evolving data environments.
Despite these advantages, narrow tables introduce their own challenges. The need for joins increases query complexity, especially when dealing with large datasets. Poorly optimized joins can lead to performance bottlenecks, negating the efficiency gained from reduced data scanning. Additionally, for business users and analysts, navigating multiple tables can make reporting more difficult without a well-defined semantic layer.
The real cost difference between wide and narrow tables becomes evident in analytics workloads at scale. In cloud environments where pricing is based on data scanned or compute time, wide tables can significantly inflate operational expenses. Even simple queries may process large volumes of irrelevant data. Narrow tables, while more efficient in terms of resource usage, require careful optimisation of joins, indexing, and partitioning strategies to maintain performance.
Another critical factor is data freshness and pipeline efficiency. Wide tables often require full refreshes when schema changes occur or when new data is added, which can slow down data pipelines and increase processing time. Narrow tables, by contrast, support incremental updates more effectively, allowing faster data ingestion and transformation. This becomes particularly important in real-time or near real-time analytics scenarios where latency directly impacts decision-making.
From a governance and maintenance perspective, narrow tables offer better control. Data lineage is clearer, ownership is easier to define, and updates can be managed without affecting the entire dataset. Wide tables, while convenient for consumption, can become difficult to maintain over time, especially as the number of columns grows and business requirements evolve.
The optimal approach is rarely one or the other. High-performing data architectures often combine both strategies—using narrow tables in the backend for efficient processing and wide tables or materialised views for consumption and reporting. This hybrid approach ensures that data pipelines remain scalable while end users benefit from simplified access.
Ultimately, the decision between wide and narrow tables should be driven by workload requirements, query patterns, and cost considerations. Organisations that fail to evaluate this trade-off often face hidden inefficiencies that grow over time. By aligning data modelling strategies with modern analytics needs, businesses can reduce costs, improve performance, and build a more resilient data ecosystem.
In a data-driven world, even seemingly small design choices can have significant long-term consequences. Understanding the cost implications of wide versus narrow tables is a critical step toward building efficient, scalable, and future-ready analytics systems.