The phrase “modern data stack” has evolved from a buzzword into a practical framework for building scalable, reliable, and insight-driven organisations. By 2026, most enterprises are no longer experimenting – they are optimising. The conversation has shifted from what tools to use to what actually works in production, under real-world constraints such as cost, governance, latency, and operational complexity.
This article explores the current state of the modern data stack, the architectural patterns that have proven resilient, and the tools that continue to deliver value rather than noise.
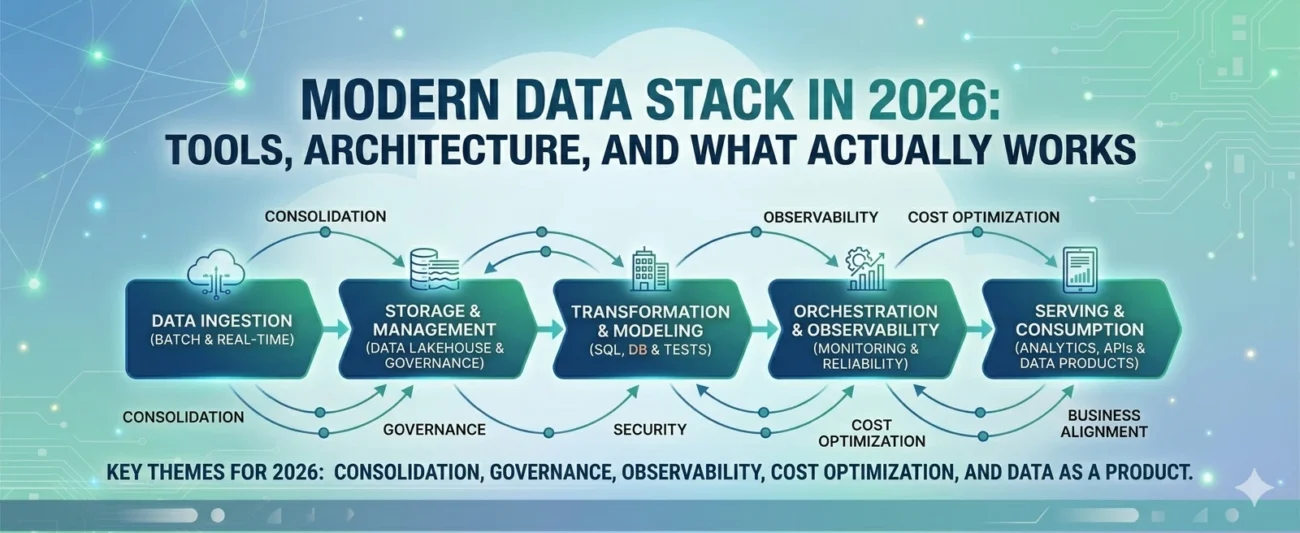
What Defines the Modern Data Stack in 2026?
At its core, the modern data stack is a modular, cloud-first ecosystem designed to ingest, transform, store, and analyse data efficiently. Unlike legacy monolithic systems, it prioritises interoperability, scalability, and separation of concerns.
In 2026, one defining characteristic stands out: consolidation over fragmentation. Organisations are actively reducing tool sprawl and favouring integrated platforms or tightly governed ecosystems.
Key principles now include:
- Cloud-native by default, but increasingly hybrid-aware
- Separation of storage and compute for flexibility and cost control
- ELT over ETL, with transformations pushed downstream
- Strong governance layers embedded across the pipeline
- Observability as a necessity, not an add-on
Reference Architecture That Actually Works
Data Ingestion Layer
Modern ingestion pipelines support both batch and real-time data, with a strong shift towards event-driven architectures and low-latency streaming.
Reliable ingestion strategies typically include change data capture (CDC) for transactional systems, API-based ingestion for SaaS platforms, and streaming pipelines for real-time analytics. The key lesson is straightforward: simplicity outperforms over-engineering. Standardised ingestion patterns consistently reduce operational failures.
Storage Layer (Data Lakehouse Dominance)
The data lakehouse model has become the dominant approach, combining the flexibility of data lakes with the performance and governance of data warehouses. Successful implementations rely on open table formats, clear separation between raw, curated, and consumption layers, and minimal duplication of datasets. What matters in 2026 is not just storing data cheaply, but ensuring it is queryable, governed, and reliable at scale.
Transformation Layer
SQL remains dominant, but transformation practices have matured significantly. The focus is now on declarative transformations, version-controlled pipelines, and built-in testing and validation. The real shift is cultural rather than technical. Data teams are adopting software engineering discipline, treating pipelines as production-grade code rather than informal scripts.
Orchestration and Workflow Management
Orchestration has evolved from simple scheduling into dependency-aware, event-driven workflow management. Effective approaches prioritise clear DAG structures, robust retry mechanisms, and seamless integration with observability tools. Overly complex orchestration frameworks often introduce more problems than they solve, making clarity and maintainability the real differentiators.
Data Serving and Consumption
The consumption layer is where business value is realised. In 2026, this goes far beyond dashboards into embedded analytics, reverse ETL, and data APIs powering real-time decisions. Traditional BI tools still play a role, but the broader trend is towards treating data as a product rather than a reporting output.
Tooling Landscape: What Stands the Test of Time
Consolidation Over Tool Sprawl
One of the clearest lessons from the past decade is that more tools do not necessarily produce better outcomes. Many organisations are now rationalising their stacks. Tools that continue to deliver value tend to share common characteristics: strong ecosystem support, clear documentation, native cloud integration, and the ability to scale without disproportionate cost increases. Niche tools with overlapping functionality are steadily being phased out in favour of streamlined ecosystems.
The Rise of Platform Thinking
Rather than stitching together numerous point solutions, organisations are increasingly adopting platform-centric architectures.
This includes unified data platforms, integrated governance and security layers, and centralised metadata management. The outcome is improved reliability, reduced operational overhead, and stronger alignment between technical and business teams.
Governance, Security, and Compliance by Design
Governance is no longer an afterthought. It is embedded across every layer of the data stack.
Key priorities include fine-grained access control, comprehensive data lineage tracking, automated compliance checks, and encryption or masking by default. Regulatory pressures and growing data sensitivity mean that security is now foundational to architecture rather than an optional enhancement.
Observability and Reliability: The Missing Piece Now Solved
Data observability has become a core pillar of the modern stack. Organisations actively monitor data freshness, latency, schema changes, pipeline failures, and quality anomalies.
The shift is towards proactive monitoring rather than reactive troubleshooting. Mature teams treat data incidents with the same urgency as application outages, reflecting the critical role of data in operations.
Cost Optimisation: From Afterthought to Strategy
Rising cloud costs have forced a more disciplined approach to architecture. Cost optimisation is now built into design decisions rather than addressed retrospectively.
Effective strategies include workload-aware compute scaling, storage tiering, query optimisation, caching, and reducing unnecessary data movement. The most successful organisations balance performance with cost efficiency instead of prioritising one at the expense of the other.
Common Pitfalls to Avoid
Overengineering the Stack
Adopting too many tools without a clear justification leads to unnecessary complexity and fragility.
Ignoring Data Modelling
Even with advanced tooling, poor data modelling results in unreliable insights and inconsistent reporting.
Lack of Ownership
Without clearly defined ownership, data pipelines degrade over time and accountability becomes unclear.
Underestimating Change Management
Technology alone does not deliver value. Processes and people must evolve alongside the stack to realise its full potential.
What Actually Works in 2026
After years of experimentation, several consistent truths have emerged. Simplicity scales more effectively than complexity, governance must be built in from the outset, and fewer well-integrated tools outperform fragmented ecosystems.
Data teams that operate with engineering discipline consistently outperform those that rely on ad hoc practices. Most importantly, alignment with business outcomes matters far more than technical perfection.
Conclusion: From Modern to Mature
The modern data stack in 2026 is no longer defined by novelty but by maturity. Organisations that succeed prioritise clarity, governance, and operational excellence over constant experimentation.
The real question is no longer whether a business is using a modern data stack, but whether that stack is delivering consistent, measurable value. That distinction ultimately defines what works today.